
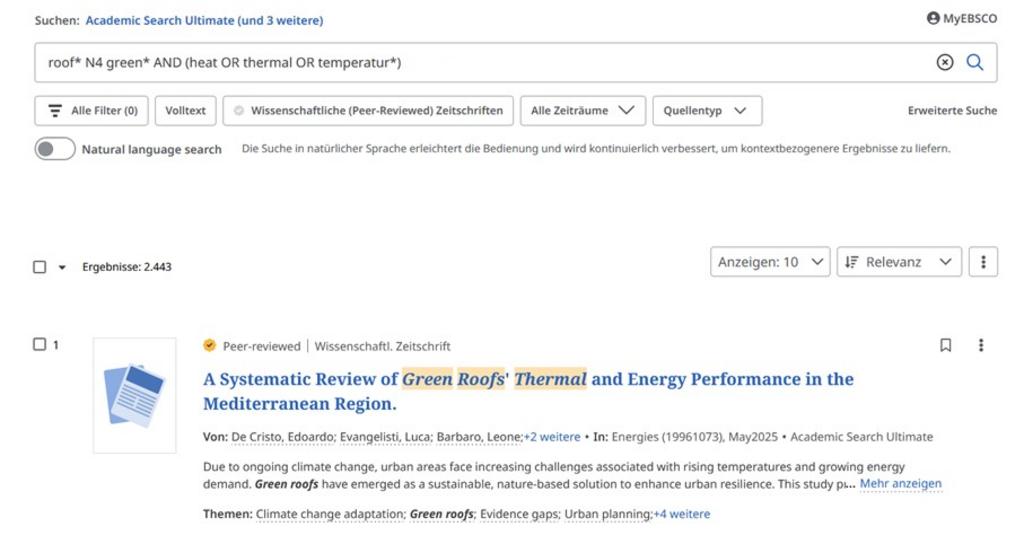
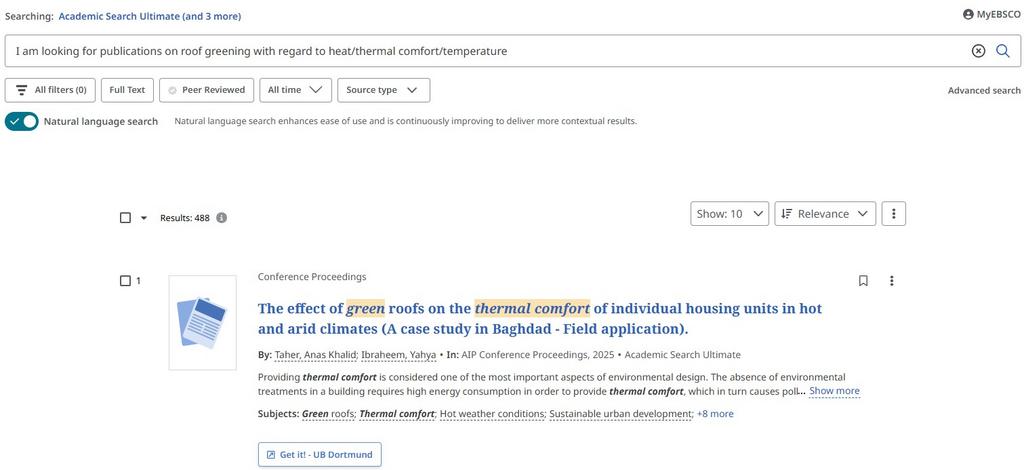
Natürlichsprachige Recherche in EBSCO
Ab sofort können Suchanfragen in allen EBSCO Datenbanken der TU Dortmund anstatt mit Boole’schen Operatoren auch in Satzform erfolgen, z.B. in den Datenbanken GreenFile, Engineering Source, SocIndex oder Academic Search Premier. Aktivieren Sie dazu in der einfachen Suche die Schaltfläche „Natural language search“.
Lohnt sich dennoch eine klassische Datenbanksuche? Je nach Prompt ermöglicht eine Boole’sche Query gegebenenfalls präzisere Abfragen und vollständigere Suchergebnisse (Bild Nr. 2)
OpenAlex – the New (Open Data) Kid on the Block
Mit OpenAlex gibt es seit 2022 eine fachübergreifende, freie Literatur- und Zitationsdatenbank. Betrieben wird OpenAlex von der gemeinnützigen Organisation OurResearch. Mit über 240 Mio. Publikationen aus allen Wissenschaftsgebieten und Weltregionen ist OpenAlex deutlich umfassender als die bekannten Zitationsdatenbanken. Während letztere auf eine strenge Auswahl der indexierten Zeitschriften setzen, erfolgt bei OpenAlex allerdings keine Kuratierung der enthaltenen Dokumente, den Anwender*innen obliegt daher die Bewertung der Inhalte.
Neben einem Grundstock an Daten aus dem Microsoft Academic Graph Projekt (einer mittlerweile eingestellten Zitationssuchmaschine ähnlich Google Scholar) bilden die Metadaten der DOI-Registrierungsagentur CrossRef die stetig wachsende Datengrundlage von OpenAlex. Nicht ganz zufällig ist der Name eine Anspielung auf die Bibliothek von Alexandria.
Auch der erste Teil des Namens ist Programm, denn OpenAlex versteht sich als Teil der Open Science Bewegung: Die Publikations- und Zitationsdaten in OpenAlex sind Open Data und stehen unter einer CC-0 Lizenz, d.h. sie sind gemeinfrei und können in beliebigen wissenschaftlichen wie auch kommerziellen Kontexten genehmigungs- und vergütungsfrei verwendet werden.
Neben einer Weboberfläche für die konventionelle Literaturrecherche bietet OpenAlex eine gut dokumentierte öffentliche API, die auch aus einschlägigen R- oder Python-Bibliotheken oder dem Netzwerk-Visualisierungstool VOSviewer abgerufen werden kann. Gerne steht die Bibliometrische Beratungsstelle der Universitätsbibliothek Mitgliedern der TU bei Fragen zu OpenAlex sowie für maßgeschneiderten bibliometrische Auswertungen zur Verfügung.
KI-Tools für die Literaturrecherche
Die Literaturrecherche in allgemeinen generativen KI-Anwendungen wie ChatGPT, Perplexity und Co. führt weiterhin häufig zu halluzinierten oder kreativ zusammengewürfelten Quellenangaben. Es gibt jedoch eine Reihe spezialisierter Anwendungen, die gezielt in wissenschaftlicher Literatur suchen und dabei neben natürlichsprachigen Suchanfragen auch eine Analyse der gefundenen Literatur anstreben.
Anwendungen wie beispielsweise Consensus oder Elicit setzen „retrieval-augmented generation“ ein, d.h. sie geben auf eine natürlichsprachige Anfrage hin also nicht einfach eine statistisch wahrscheinliche Textfolge aus, sondern wählen mittels Vektorsuche passende Datensätze aus einem designierten Datenpool – in diesem Fall Literaturdaten – und generieren auf deren Basis eine Antwort. Die Auswertung der Literatur erfolgt bei diesen und vergleichbaren Anwendungen meist anhand der Metadaten, in manchen Fällen auch anhand von Abstracts. Teilweise bieten sie Zusatzfunktionen zur Auswertung von Volltexten, die in den frei verfügbaren Versionen oft auf Open Access Dokumente beschränkt ist.
Nicht verschwiegen werden sollte jedoch, dass Halluzinationen auch bei dieser Art von Anwendungen nicht ausgeschlossen, sondern nur minimiert werden können. Hinzu kommt die schlechte Nachvollziehbarkeit der zugrundeliegenden Daten, Such- und Rankingalgorithmen sowie die fehlende Reproduzierbarkeit von Suchergebnissen. KI-Recherchetools stellen aktuell daher keinen Ersatz, sondern nur eine Ergänzung der klassischen Literaturrecherche dar.
Wie andere KI-Anwendungen sind die meisten dieser Tools „freemium“-Modelle, bei der eine eingeschränkte Anzahl an Suchen kostenfrei, teils auch ohne vorherige Registrierung möglich ist, um die Anwendung zu testen. Eine Auswahl KI-gestützter Recherche-Tools stellt die Universitätsbibliothek auf ihren Webseiten vor.
Umbrüche im wissenschaftlichen Publikationswesen
Auch im Publikationswesen sorgt KI für Umwälzungen: Autor*innen und Verlage sehen sich mit der Frage konfrontiert, in welchem Ausmaß generative KI im Schreib - und Publikationsprozess eingesetzt werden sollte und wie der Einsatz kenntlich zu machen ist. Die Diskussion berührt neben urheber- und datenschutzrechtlichen Belangen vor allem die Frage nach guter wissenschaftlicher Praxis. Eine kürzlich in Nature erschienene Umfrage zeigt, wie gespalten die Einschätzungen dazu unter Forschenden sind. Die meisten Verlage geben ihren Autor*innen und Reviewenden bereits mehr oder weniger ausführliche Richtlinien zur Nutzung von AI an die Hand, so z.B. Elseviers AI-Richtlinie für Journalbeiträge, Wileys ausführliche Richtlinie für Buchautor*innen und Ethics Vorgaben im Journalbereich, die AI-Policies für die unterschiedlichen SpringerNature Imprints, oder Sages AI-Policy. Nach den Generative AI In Scholarly Communications Guidelines der Association of STM Publishers von Ende 2023 befinden sich aktuell Recommendations for a Classification of AI Use in Academic Manuscript Preparation in Abstimmung, die den im Verband organisierten Verlagen Orientierung bei der Anpassung ihrer eigenen Richtlinien geben soll.
Besonders im Begutachtungsverfahren, das sich angesichts zunehmender Einreichungen und nicht im gleichen Maß steigenden Zahlen an Reviewenden in einer veritablen Krise befindet, ist ein Austarieren von Effizienzgewinnen und ethisch vertretbarem KI-Einsatz zu beobachten. Das Hochladen von Einreichungen in KI-Anwendungen von Drittanbietern läuft nicht nur dem Urheber- und Datenschutzrecht zuwider und lässt sich mit den Policies der Verlage nicht vereinbaren, sondern bricht vor allem, wie es ein kanadischer Wissenschaftler formuliert, den Gesellschaftsvertrag des Begutachtungsverfahrens: „I submit a manuscript for review in the hope of getting comments from my peers. If this assumption is not met, the entire social contract of peer review is gone. In practical terms, I am fully capable of uploading my writing to ChatGPT“. Um Herausgeber und Reviewende jedoch von automatisierbaren Teilen des Prozesses zu entlasten, entwickeln Verlage hauseigene, geschlossene KI-Systeme oder kaufen entsprechende Tools ein. Die von Springer eingesetzten Tools u.a. zur Überprüfung von Grafiken werden dabei nicht das letzte Beispiel bleiben.
Mit großer Aufmerksamkeit verfolgen die großen Verlage außerdem die zahlreichen laufenden Gerichtsverfahren zwischen Content-Anbietern und KI-Unternehmen bezüglich der ungefragten (und zunächst unvergüteten) Nutzung urheberrechtlich geschützter Inhalte als Trainingsdaten. Erste Urteile aus den USA sind zugunsten einer fair use Interpretation gefallen, die eine ausreichend „transformative Verwendung“ der Inhalte voraussetzt. Dies waren aber noch lange nicht die letzten Urteile in dieser Frage - und selbst wenn sich die Interpretation durchsetzen sollte, dass die Verwendung als Trainingsdaten fair use darstellt, könnte zumindest für illegal erlangte Daten nachträglich noch Schadenersatz in empfindlicher Höhe fällig werden. Kommentare zu den ersten Verfahren und Urteilen finden sich u.a. im Branchennewsletter The Brief, bei Scholarly Kitchen sowie der Authors‘ Alliance.
Während die Gerichtsverfahren um die Verwendung ihrer Inhalte als Trainingsdaten laufen, stellen sich insbesondere für Wissenschaftsverlage, aber auch für ihre Autor*innen Zielkonflikte im Umgang mit den KI-Firmen: So haben Verlage wie Forschende einerseits ein großes Interesse an der Auffindbarkeit ihrer Inhalte auch in KI-Anwendungen, müssen andererseits aber vor allem die korrekte Attribuierung von und Weiterleitung potenzieller Lesender zu den Originaltexten sicherstellen. Diese Spannung zeigt sich beispielhaft bei Verlagen wie Wiley, die sich einerseits gegen Content Scraping durch KI-Unternehmen verwehren, andererseits aber auch Kooperationen mit den einschlägigen Firmen eingehen. Ein entsprechender Vertrag zwischen Microsoft und der Muttergesellschaft von Taylor & Francis hat dabei im vergangenen Jahr für großen Unmut unter den Autor*innen gesorgt, die weder vorab informiert wurden noch eine Widerspruchsmöglichkeit hatten. Der Verlag gibt an, im Vertrag mit Microsoft Vorgaben zum erlaubten Umfang wörtlicher Zitate und zur obligatorischen Referenzierung der Originaldokumente verankert zu haben, und hat angekündigt, Autor*innen an den (nicht unbeträchtlichen) Zusatzeinnahmen beteiligen zu wollen.
Fragen und Kontakt
Ihre Fachreferentin der Universitätsbibliothek, Ursula
Helmkamp
raumplanung.ub@tu-dortmund.de
0231 – 755 4037